
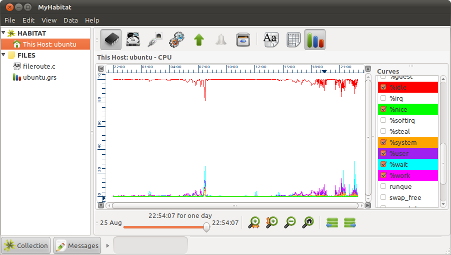
Habitat
Habitat from System Garden is extensible collector, monitor and viewer for system and applications. A gateway into System Garden for social IT management.A fast, graphical desktop tool lets you browse live performance data from the local client and other hosts that also run Habitat. Data sets can come from desktops or servers using Habitat colection agents, from System Garden Repositories over the internet or from your own CSV files or data feeds.
It is able to pan and zoom into live or stored data sets to show information taken over years and quickly drill down in to a timebase of seconds.
The Data

The core of habitat provides a mechanism for collecting, storing and distributing data. Out of the box are many useful collectors of system information, which include cpu, virtual memory, storage, processes and network statistics (full list).
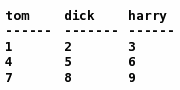
Any user data can be added for time series tracking from either the graphical tool or the command line. Scripting languages of all types can send data to a habitat file or the repository, even in real time! For developers there is an API for extending the collector (called clockwork) with plug-ins, allowing data to be pulled in from other sources created by users. If the data can be made to look like a series of tables, then it can live with habitat (providing its text and numbers!).
In Depth
For more information
- Look at Habitat's main features including the GUI MyHabitat
- Review the On-line documentation, which is also availble in a download PDF form or ePub.
Platforms

Habitat is currently running under Linux (2.4 and 2.6 kernels) and Solaris (version 7 onwards) with initial versions for MacOS X (10.6). Binary RPMs are available for Centos, Fedora and Mandriva, tarballs for Ubuntu and Mac (no collection yet).
Habitat is licensed under GPL version 3. Enjoy!